BackTensor Calculus Introduction
Tensor calculus is an extension of vector calculus to tensor fields. These tensor fields may vary over a manifold. Tensor calculus makes use of indices:
xμxμcontravariant,covariant. A vector x may be decomposed into a linear combination of components and basis vectors. In Cartesian coordinates, with components x, y, z and basis vectors i^, j^, k^, x is equal to:
x=xi^+yj^+zk^. For a general vector x with components xμ and basis vectors eμ, the vector is equal to:
x=μ∑xμeμ. Sums like these appear a lot in tensor calculus, so we use the Einstein summation convention - when an index appears twice - once as upper (contravariant) and once as lower (covariant), it implies summation over the set:
x=xμeμ. The vector x is invariant - the vector remains unchanged after transformations (in this context coordinate transformations). However, the components xμ and the basis vectors eμ are variant.
A general type-(n,m) tensor T is a linear combination of basis vectors eμ and basis covectors ϵμ:
T=Ti1...ini1...imei1...einϵi1...ϵim. The vector is a member of vector space. A vector space is a collection (V,S,+,⋅) where V is a set of vectors, S is a set of scalars, + is a vector addition rule and ⋅ is a vector scaling rule. Vectors are "things" that we can add together (+):
(a+b)μ[a1a2]+[b1b2]=aμ+bμ,=[a1+b1a2+b2], and scale (⋅):
(na)μn[a1a2]=naμ,=[na1na2]. To start with covectors, they can be though of as row vectors [x1x2] (note the covariant index). Flipping a vector to a row vector only works in orthonormal basis (perpendicular bases and one unit long).
We can think of row vector as a function on a column vector and to find a value we do the standard matrix multiplication:
[a1a2]([b1b2])=b1a1+b2a2=bμaμ. Covectors have two properties. The first one is we can add inputs or add outputs and get the same answers:
a(b+c)[a1a2]([b1b2]+[c1c2])[a1a2]([b1b2]+[c1c2])=a(b)+a(c),=[a1a2]([b1+c1b2+c2])=(b+c)μaμ=(bμ+cμ)aμ,=[a1a2]([b1b2])+[a1a2]([c1c2])=bμaμ+cμaμ=(bμ+cμ)aμ. The second property is that we can scale the input or scale the output and get the same answers:
a(nb)[a1a2](n[b1b2])=na(b),=[a1a2]([nb1nb2])=a1nb1+a2nb2=n(a1b1+a2b2)=n[a1a2]([b1b2]). These two properties together are called linearity:
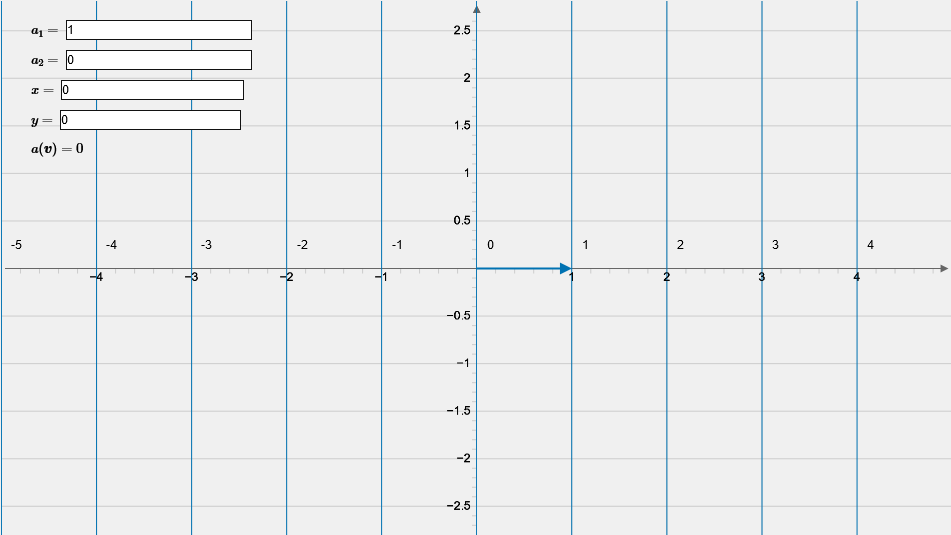
a(nb+mc)=na(b)+ma(c). Vectors could be visualized by arrows. Covectors could also be visualized by vectors, but since they are functions, it would not be ideal. A better way is to use curves of constant output value C. Consider a covector with components aμ and a vector with components x and y:
[a1a2]([xy])yx=a1x+a2y=C,=a2C−a1x,=a1C−a2y,(a2=0)(a1=0) if we represent the covector as an arrow, it will point perpendicular to the curves and into the direction of increase.
From the applet, we can see that the output can be visualized as the number of lines the vector pierces.
The following holds true for summing covectors:
(a+b)(v)([a1a2]+[b1b2])([v1v2])=a(v)+b(v),=([a1+b1a2+b2]([v1v2])=(a1+b1)v1+(a2+b2)v2=a1v1+b1v1+a2v2+b2v2=a1v1+a2v2+b1v1+b2v2=[a1a2]([v1v2])+[b1b2]([v1v2]), and the following for scaling:
(na)(v)(n[a1a2])([v1v2])=na(v),=([na1na2])([v1v2])=na1v1+na2v2=n(a1v1+a2v2)=n[a1a2]([v1v2]) A similar abstract definition can be made: covector is a member of dual vector space (V∗,S,+,⋅), where elements of V∗ are covectors, V→R. Below is a definition of vectors, covectors and their corresponding spaces:
Vectors are members of vector space (V,S,+,⋅)Vset of vectorsSset of scalars+(v+w)μ=vμ+wμ⋅(nv)μ=nvμCovectors are members of dual vector space (V∗,S,+,⋅)V∗set of covectors (functions) - V→RSset of scalars+(a+b)(v)=a(v)+b(v)⋅(na)(v)=na(v)Additional properties (linearity):a(v+w)=a(v)+a(w)a(nv)=na(v) Consider a curve parametrized by λ, R(λ):
where the green vector is the tangent vector. In the limiting case when h→0:
h→0limhR(λ+h)−R(λ)=dλdR. By chain rule, the tangent vector may be written out:
dλdR=∂Rμ∂RdλdRμ. Note: the terms are summed over the μ components. The term dλdRμ makes sense, it's just the derivative of components of R. But the ∂Rμ∂R may look a bit weird. To make sense of it, remember that R is the linear combination of the components Rμ and basis vectors eμ:
R∂Rμ∂R=Rμeμ,=∂Rμ∂(Rμeμ)=∂Rμ∂(R1e1+...+Rμeμ+...)=∂Rμ∂(R1e1)+...+∂Rμ∂(Rμeμ)+...=0+...+eμ+...=eμ, meaning the partial derivative of vector with respect to its component is the basis vector of that component:
∂Rμ∂R=eμ, however, this definition when we work with intrinsic definitions (if we live on the curve on the image above, we don't have an origin, thus we cannot specify R), we have to use a different definition:
∂xμ∂≡eμ, where I replaced Rμ with xμ. I will sometimes use ∂Rμ∂R and sometimes ∂xμ∂. This new definition is on vector space of derivative operators, also called tangent vector space TpM - vector space of derivatives at point p on the surface M.
The fact that covectors may be represented by differentials may seem a bit weird initially - how does a covector relate to the differential (e.g. dx) as are in derivatives and integrals. The multivariable differential is equal to:
df=∂xμ∂fdxμ, or in one dimension:
df=dxμdfdxμ. We are used that for a variable x, the differential dx means a small change in x. We need to redefine it such that f is a scalar field and df is a covector field.
Consider a function f(x,y)=x+y:
The differential df is equal to:
df=∂x∂fdx+∂y∂fdy=dx+dy, where dx and dy are the dual basis (will be explained later). The covector field may also be written as follows:
df=[11]. If we input this covector into the applet above, we can visualize the covector field. The lines are the levels of constant f:
The covector df(v) is proportional to the steepness of f and to the length of v. From this, we can say that df(v) gives us the rate of change of f when moving in the direction of v, which is the directional derivative of f in the direction of v:
df(v)=∇vf=∂v∂f. Consider covector field df acts on the basis vectors ∂x∂ and ∂y∂:
df(∂x∂)df(∂y∂)=∂x∂f,=∂y∂f.(directional derivative of f in the x direction)(directional derivative of f in the y direction) Now, consider the scalar field x, where the value is just the value of x at the point:
the covector field dx looks like this:
and the covector field dx acts on the basis vectors ∂x∂ and ∂y∂ as follows:
dx(∂x∂)dx(∂y∂)=∂x∂x=1,=∂y∂x=0.(directional derivative of x in the x direction)(directional derivative of x in the y direction) Similarly, the covector field dy acts on the basis vectors ∂x∂ and ∂y∂ as follows:
dy(∂x∂)dy(∂y∂)=∂x∂y=0,=∂y∂y=1.(directional derivative of y in the x direction)(directional derivative of y in the y direction) So we introduce special covectors ϵμ called the dual basis, such that:
ϵμ(eν)=δνμ, where δνμ is the Kronecker delta:
δνμ={10μμ=ν,=ν. Which is identical to the previous equations with differentials and derivatives:
dxμ(∂xν∂)=∂xν∂xμ=δνμ. The derivative of f with respect to λ may be rewritten as the covector df acting on the vector dλd:
dλdf=df(dλd).